[Tensorflow]14.MNIST 98%
in Language on tensorflow
14.MNIST 98%
이번 장에서는 MNIST예제를 neural network를 적용하여 작성해보겠습니다.
저번에 neural network를 사용하지 않았을 때는 91%의 정확도가 나왔는데 과연 어느정도 성능이 향상 될까요???
시작해보겠습니다.
먼저, 맨 처음 tensorflow를 import~~!
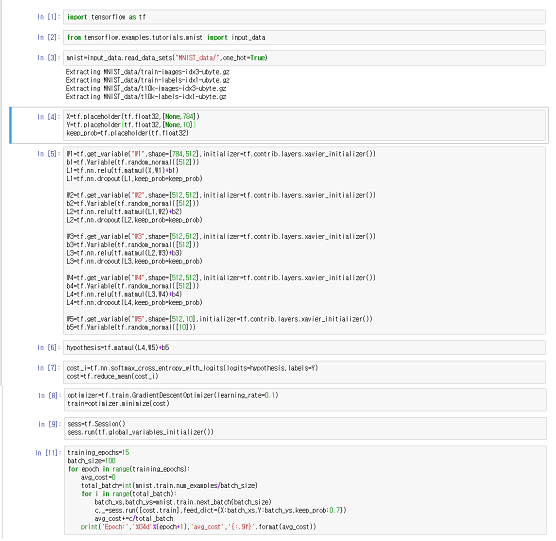
import tensorflow as tf
그리고 학습 데이터를 가져오기 위해 다음을 입력해줍니다
from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
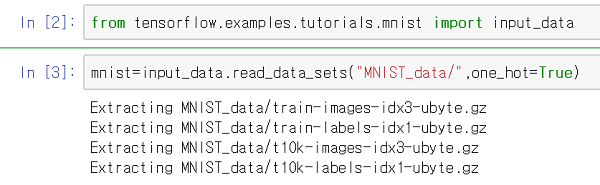
그러면은 위와 같이 tensorflow가 데이터를 알아서 가져와줍니다.
그 다음 학습에 필요한 변수들 선언!
X=tf.placeholder(tf.float32,[None,784]) Y=tf.placeholder(tf.float32,[None,10]) keep_prob=tf.placeholder(tf.float32)#drop out에 사용되는 것입니다.
Layer 구축
#input layer W1=tf.get_variable("W1",shape=[784,512],initializer=tf.contrib.layers.xavier_initializer()) b1=tf.Variable(tf.random_normal([512])) L1=tf.nn.relu(tf.matmul(X,W1)+b1) L1=tf.nn.dropout(L1,keep_prob=keep_prob) #hidden layer1 W2=tf.get_variable("W2",shape=[512,512],initializer=tf.contrib.layers.xavier_initializer()) b2=tf.Variable(tf.random_normal([512])) L2=tf.nn.relu(tf.matmul(L1,W2)+b2) L2=tf.nn.dropout(L2,keep_prob=keep_prob) #hidden layer2 W3=tf.get_variable("W3",shape=[512,512],initializer=tf.contrib.layers.xavier_initializer()) b3=tf.Variable(tf.random_normal([512])) L3=tf.nn.relu(tf.matmul(L2,W3)+b3) L3=tf.nn.dropout(L3,keep_prob=keep_prob) #hidden layer3 W4=tf.get_variable("W4",shape=[512,512],initializer=tf.contrib.layers.xavier_initializer()) b4=tf.Variable(tf.random_normal([512])) L4=tf.nn.relu(tf.matmul(L3,W4)+b4) L4=tf.nn.dropout(L4,keep_prob=keep_prob) #output layer W5=tf.get_variable("W5",shape=[512,10],initializer=tf.contrib.layers.xavier_initializer()) b5=tf.Variable(tf.random_normal([10]))
hypothesis 정의
hypothesis=tf.matmul(L4,W5)+b5
cost 함수 정의
cost_i=tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis,labels=Y) cost=tf.reduce_mean(cost_i)
cost 최소화
#실제 값과 예측 값의 차이를 계속 줄여준다. optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.1) train=optimizer.minimize(cost)
노드들을(tensor) 그래프 화
sess=tf.Session() #변수 초기화 sess.run(tf.global_variables_initializer())
데이터가 많기에 역시 batch 시스템을 이용합니다~~~!
저번 예제와 학습하는데 사용하는 코드는 똑같습니다.
다만 feed_dict 부분에 dropout에 이용되는 keep_prob이 추가됩니다~
training_epochs=15 #15번 거쳐서 학습을 시킨다 batch_size=100 #100개 씩 데이터를 가져온다 for epoch in range(training_epochs): avg_cost=0 #학습 1번 당 평균 cost값 #데이터의 총 갯수를 100으로 나누어준다. -> 몇 번에 거쳐 데이터를 가져올 지 계산 total_batch=int(mnist.train.num_examples/batch_size) for i in range(total_batch): #100개 씩 데이터를 가져와 학습시킨다. batch_xs,batch_ys=mnist.train.next_batch(batch_size) c,_=sess.run([cost,train],feed_dict={X:batch_xs,Y:batch_ys,keep_prob=0.7}) avg_cost+=c/total_batch print('Epoch:','%04d'%(epoch+1),'avg_cost','{:.9f}'.format(avg_cost))
학습 끝! 학습할 때마다 점점 cost 값이 줄어드시는 것을 볼 수 있습니다.
층이 많다보니 학습하는데 시간 좀 걸리네요ㅠㅠㅠ

과연 학습이 잘 되었나 확인해볼까요?
tensorflow에서 기본적으로 제공하는 test데이터를 이용해서 정확도를 측정해보겠습니다.

놀랍게도 정확도는 97.7%까지 나옵니다~~ 대단합니다!
딥러닝의 위대함을 다시 한번 느끼게 되네요~
다음 장에서는 Neural Network의 응용인 CNN에 대해 배워보겠습니다
전체 코드

배움은 의무도 생존도 아니다