[Tensorflow]3.Linear Regression(2)
in Language on tensorflow
Linear Regression(2)
2.Linear Regression(1) 에 이어서 포스팅을 하겠습니다.
이번에는 tensorflow로 처음부터 끝까지 간단하게 데이터를 훈련시키고 예측까지 시켜보겠습니다.
전 장에서 언급한 예제인 어떤 학생의 수학 점수를 입력하면 대학 합격 유무를 알려주게끔 학습을 시켜 보겠습니다.
5명의 데이터를 가지고 학습을 시키겠습니다. 실제로는 엄청 많은 학습데이터가 필요하죠~~
여기서는 머신러닝(기계학습)이 tensorflow에서 어떤 식으로 동작하는지 이해하는 것에 초점을 두시기 바랍니다.
그럼 시작하겠습니다~ (코드 작성은 jupyter notebook을 사용하는 것이 편합니다.)
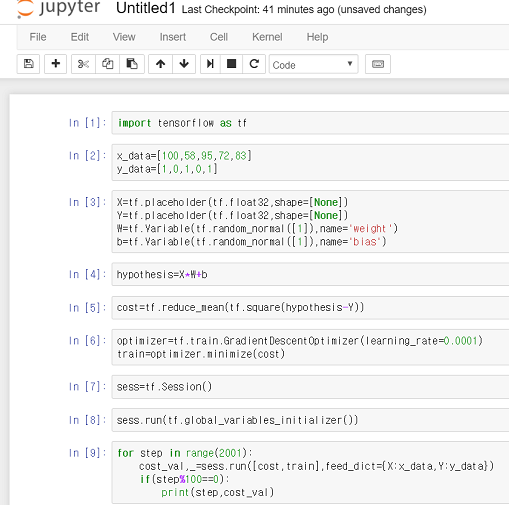
먼저, 맨 처음 tensorflow를 import~~!
import tensorflow as tf
그리고 우리가 사용할 데이터 실제 올해 합격한 대학생의 데이터입니다.
x_data=[100,58,95,72,83] #학생1 100점,학생2 58점,학생3 95점, 학생4 72점,학생5 83점 y_data=[1,0,1,0,1] #합격 불합격 합격 불합격 합격
그 다음 학습에 필요한 변수들 선언!
#데이터를 담을 틀이라 생각 X=tf.placeholder(tf.float32,shape=[None]) Y=tf.placeholder(tf.float32,shape=[None]) #컴퓨터가 학습시키면서 변경하는 변수 W=tf.Variable(tf.random_normal([1]),name='weight') b=tf.Variable(tf.random_normal([1]),name='bias')
hypothesis 정의
#데이터를 구분짓는 직선(예측 값) hypothesis=X*W+b
cost 함수 정의
#예측 값과 실제 값의 차이 cost=tf.reduce_mean(tf.square(hypothesis-Y))
cost 최소화
#실제 값과 예측 값의 차이를 계속 줄여준다. optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.0001) train=optimizer.minimize(cost)
노드들을(tensor) 그래프화
sess=tf.Session() #변수 초기화 sess.run(tf.global_variables_initializer())
학습을 시작합니다~
#반복문을 돌면서 계속 데이터를 넣는다->w,b가 cost가 최소가 되게 계속 이동 for step in range(2001): cost_val,_=sess.run([cost,train],feed_dict={X:x_data,Y:y_data})}) if(step%100==0): print(step,cost_val)
학습 끝! step마다 cost가 줄어드는 것을 보실 수 있습니다.

과연 학습이 잘 되었나 확인해볼까요? 수학 점수 92점일 때 결과는??
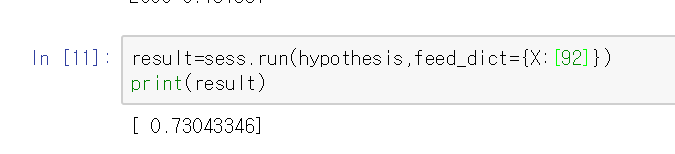
0보다는 1이 더 가깝죠?? 따라서 합격이라고 예측!
수학 점수 58점일 때 결과는??

1보다는 0이 더 가깝죠?? 따라서 불합격이라고 예측!
생각보다 잘 작동하는 것 같아 보입니다.
하지만 우리가 원하는 것은 0(불합격)이면 딱 0, 1(합격)이면 딱 1로 반환해줬으면 하는 건데요!!
또 실제로 저 예측값이 항상 0과 1사이인지도 의문입니다.
이것을 해결하여 주는 것이 조금 뒤에 배울 분류(classification)입니다!!!!
일단은 예제 실행해보시고 머신러닝에 대해 대충이라도 이해하셨으면 좋겠습니다!
전체 코드

배움은 의무도 생존도 아니다