[Oracle] 30.인덱스
인덱스
인덱스란 SQL 명령문의 처리 속도를 향상시키기 위해서 컬럼에 대해서 생성하는 오라클 객체입니다.
예를 들어 책에서 어떤 내용을 찾으려고 할 때 책 첫 페이지부터 한 장씩 넘겨가면서 테이블 생성 방법이 기술되어 있는지 일일이 살펴보는 사람은 드물 것입니다.
일반적으로 책 맨 뒤에 있는 색인(인덱스, 찾아보기)에서 해당 내용을 찾아 그 페이지로 이동합니다.
이렇게 원하는 단어를 쉽게 찾는 방법으로 색인, 인덱스가 사용되는 것처럼 오라클의 인덱스 역시 원하는 데이터를 빨리 찾기 위해서 사용됩니다.
인덱스는 99.9% 검색을 위해 사용되는데요~
그 이유는 오라클에서의 인덱스의 내부 구조는 B* 트리 형식으로 구성되어 있습니다.
컬럼에 인덱스를 설정하면 이를 위한 B* 트리도 생성되어야 하기 때문에
인덱스를 생성하기 위한 시간도 필요하고 인덱스를 위한 추가적인 공간이 필요하게 됩니다.
인덱스를 수정하면 B* 트리도 같이 수정되야하기에 DML에 인덱스를 사용하면, 사용하지 않는 것보다 작업이 훨씬 무거워집니다!
B* 트리는 B-트리를 변형한 것인데, B-트리에 관련된 내용은 [자료구조] 1.B-tree 에 포스팅 해놓았습니다!
인덱스 생성
인덱스는 기본키나 유일키와 같은 제약조건을 지정하면 따로 생성하지 않더라도 자동으로 생성해줍니다!
기본 키나 유일 키는 데이터 무결성을 확인하기 위해하기 위해서 수시로 데이터를 검색하기 때문에
빠른 조회를 목적으로 오라클에서 내부적으로 해당 컬럼에 인덱스를 자동으로 생성하는 것입니다.
예를 들어 다음과 같이 emp 테이블을 생성해보겠습니다.
CREATE TABLE emp (
empno NUMBER PRIMARY KEY,
ename VARCHAR(2) UNIQUE,
salary NUMBER
);
그러면 empno와 ename에 각각 기본키,유일키 제약조건이 지정되었으므로 자동으로 인덱스가 생성됩니다.
확인해볼까요? 인덱스를 조회하는 방법은 다음과 같습니다.
SELECT
*
FROM
user_ind_columns
where table_name='EMP';

인덱스를 사용자가 생성하는 방법은 다음과 같습니다.
CREATE INDEX idx_emp_ename ON emp (ename);
인덱스 제거하기
인덱스 제거는 DROP문을 이용합니다!
DROP INDEX idx_emp_ename;
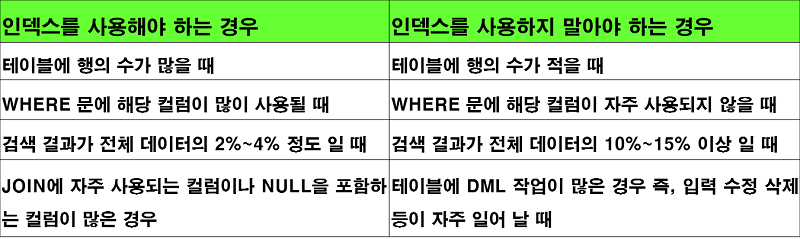
인덱스를 사용해야 하는 경우 판단하기
인덱스가 검색을 위한 처리 속도만 향상시킨다고 했습니다.
그렇다면, 무조건 인덱스를 사용한다고 검색속도가 향상될까요??
그것은 아닙니다~ 인덱스를 사용해야하는 경우와 사용하지 말아야하는 경우가 있습니다.
사용하지 말아야하는 경우에 인덱스를 사용하면, 오히려 속도가 늦어질 수도 있습니다.
인덱스의 재생성
오라클에서의 인덱스의 내부 구조는 B-트리 형식으로 구성되어 있다고 했습니다. ( [자료구조] 1.B-tree참조하시면 됩니다. )
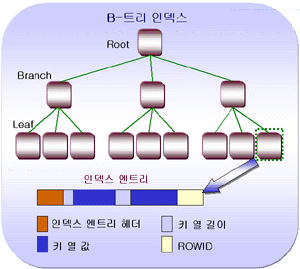
인덱스가 생성된 후에 새로운 행이 추가되거나 삭제될 수 있고, 인덱스로 사용된 컬럼값이 변경될 수도 있습니다.
이럴 경우 본 테이블에서 추가, 삭제, 갱신 작업이 일어날 때 해당 테이블에 걸린 인덱스의 내용도 함께 수정돼야 합니다.
이 작업은 오라클 서버에 의해 자동으로 일어나는데,
DELETE 문이 실행되면 인덱스 엔트리가 바로 인덱스로부터 제거되지 않고 논리적인 삭제 과정만 일어납니다.
다시 말해서, DELETE 명령을 수행한 경우에는 해당 인덱스 엔트리가 논리적으로만 제거되고
실제 인덱스 엔트리는 그냥 남아 물리적인 공간을 차지하고 있게 됩니다.
인덱스에 제거된 엔트리가 많아질 경우에는 제거된 인덱스들이 필요 없는 공간을 차지하고 있기 때문에
종종 인덱스를 재생성시켜야 합니다.
인덱스를 재생성할 때는 다음과 같이 합니다.
ALTER INDEX idx_emp_empno REBUILD;
인덱스의 종류
인덱스의 종류는 다음과 같습니다.

- 고유 인덱스
고유 인덱스(유일 인덱스라고도 부름)는 기본키나 유일키처럼 유일한 값을 갖는 컬럼에 대해서 생성하는 인덱스입니다.
-- 고유인덱스
CREATE UNIQUE INDEX idx_emp_empno ON emp (empno);
- 비 고유 인덱스
비고유 인덱스는 중복된 데이터를 갖는 컬럼에 대해서 인덱스를 생성하는 경우를 말합니다
-- 비 고유인덱스
CREATE INDEX idx_emp_ename ON emp (ename);
- 결합 인덱스
지금까지 생성한 인덱스들처럼 한 개의 컬럼으로 구성한 인덱스는 단일 인덱스입니다.
두 개 이상의 컬럼으로 인덱스를 구성하는 것을 결합 인덱스라고 합니다.
-- 결합 인덱스
CREATE INDEX idx_dept01_com ON dept01 (deptno,dname);
- 함수 인덱스
WHERE SAL = 300이 아니라 WHERE SAL12 = 3600와 같이 SELECT 문 WHERE 절에 산술 표현 또는 함수를 사용하는 경우가 있습니다.
이 경우 만약 SAL 컬럼에 인덱스가 걸려 있다면 인덱스를 타서 빠르리라 생각 할 수도 있지만,
실상은 SAL 컬럼에 인덱스가 있어도 SAL12는 인덱스를 타지 못합니다.
인덱스 걸린 컬럼이 수식으로 정의 되어 있거나 SUBSTR 등의 함수를 사용해서 변형이 일어난 경우는 인덱스를 타지 못하기 때문입니다.
이러한 수식으로 검색하는 경우가 많다면 아예 수식이나 함수를 적용하여 인덱스를 생성 할 수 있습니다.
SAL12로 인덱스를 만들어 놓으면 SAL12가 검색 조건으로 사용될 시 해당 인덱스를 타게 됩니다.
이러한 인덱스를 함수 인덱스라고 합니다.
CREATE INDEX idx_emp_annsal ON emp ( salary * 12 );
인덱스 조회 속도 비교하기
과연 인덱스를 사용하면 조회속도가 줄어들까요?
직접확인해보겠습니다
실습을 위해 emp02 테이블을 정의하겠습니다.
인덱스는 행이 많아야 효율이 좋으므로 많은 행을 삽입하겠습니다.
-- emp02 테이블 생성
CREATE TABLE emp02
AS
SELECT *
FROM employees
where 1=0;
--시퀀스 생성
CREATE SEQUENCE emp02_seq INCREMENT BY 1 START WITH 1;
--데이터 삽입
INSERT INTO emp02
SELECT emp02_seq.NEXTVAL,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
FROM
employees;
-- 충분히 많이 실행<총 876544개의 행 삽입>
INSERT INTO emp02
SELECT emp02_seq.NEXTVAL,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
FROM
emp02;
명령어가 실행되는 시간을 확인하기 위해 콘솔을 이용하겠습니다~!
콘솔에서 다음과 같이 입력하면 명령어가 실행되는 시간을 알려줍니다!
set timing on
다음 쿼리문을 실행해보겠습니다!
SELECT
*
FROM
emp02
WHERE
employee_id = 430020;
결과는 콘솔에서의 실행시간과 cost를 보기 위해 deveploper의 계획설명 기능을 이용하겠습니다!(COST는 I/O 서브시스템에 대한 요청횟수)
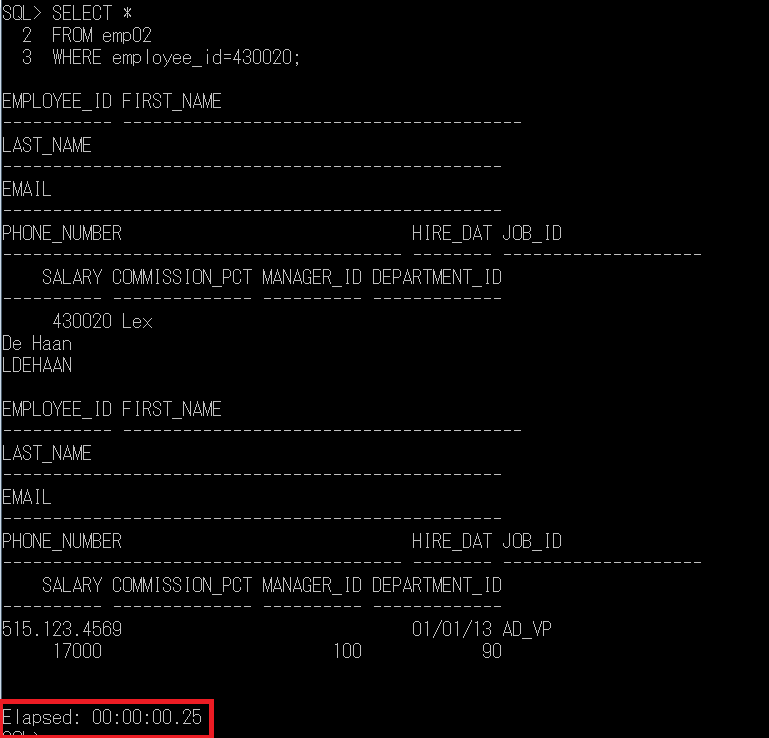
0.25초가 걸렸군요!
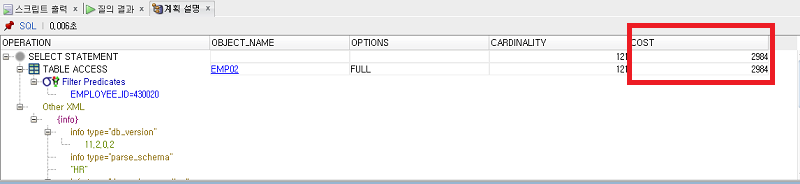
COST도 2984입니다. (디스크 접근 횟수라고 생각하시면 됩니다.)
똑같은 쿼리를 한번 더 실행해 볼까요???
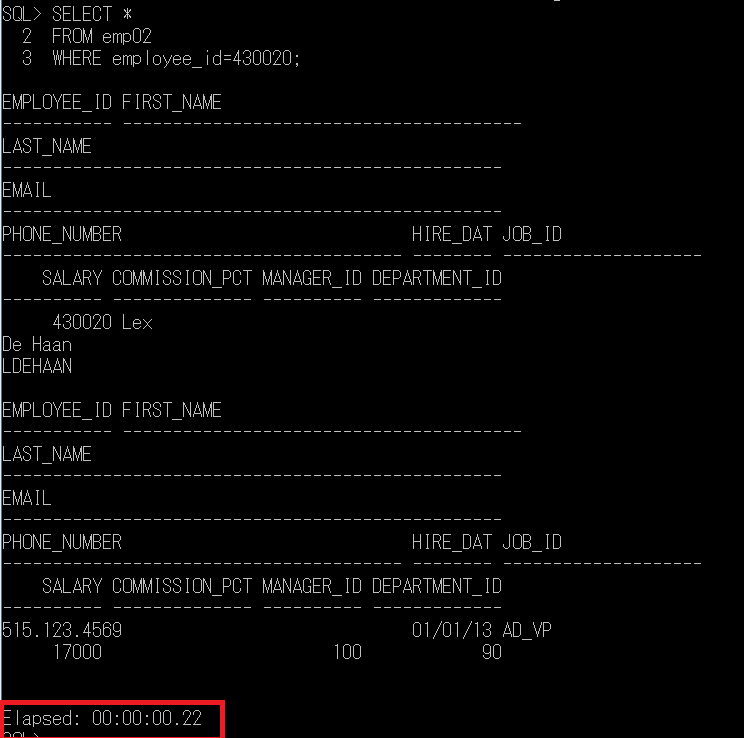
앗 0.22초네요~ 이게 어떻게 된것일까요.. 아직 인덱스를 생성하지도 않았는데..줄었습니다.
이것은 SELECT 문 쿼리를 한 번 실행하면 메모리 상에 쿼리가 올려져 있어서 시간이 단축되기 때문입니다.
따라서 정확한 시간 측정을 위해서는 쿼리 실행 전에 버퍼를 비워주어야합니다.
SYSTEM 계정에서 다음 명령어를 실행하면 버퍼가 비워집니다.
-- 버퍼 비우기(SYSTEM 계정)
ALTER SYSTEM FLUSH BUFFER_CACHE;
ALTER SYSTEM FLUSH SHARED_POOL;
앞으로 정확한 시간 측정을 위해 시간 측정할 때 마다 버퍼를 비워주겠습니다!
이제 인덱스를 생성해보겠습니다!
CREATE UNIQUE INDEX idx_emp02_empid ON emp02(employee_id);
그리고 다시 아까 쿼리를 실행해보죠!
SELECT
*
FROM
emp02
WHERE
employee_id = 430020;
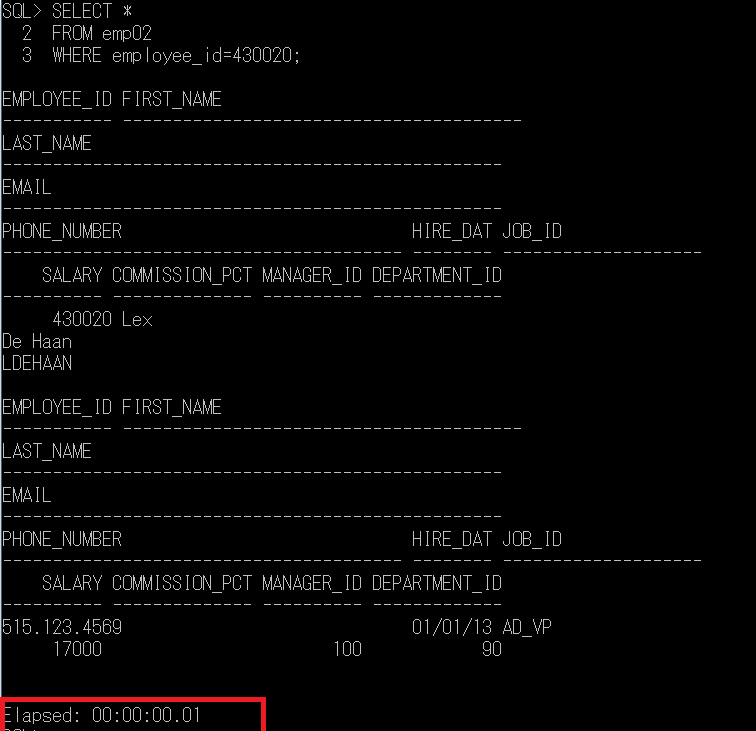
와우 0.01초입니다! (인덱스 사용 전 0.25초)
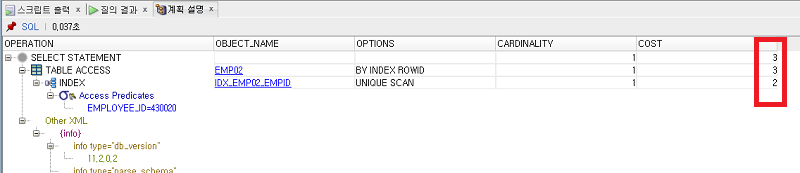
COST도 엄청나게 줄었습니다! 지금은 확연한 차이를 못느끼실테지만 데이터가 훨씬 많다면 차이가 엄청날 것입니다!
이로써 index가 검색의 효율을 높인다는 사실을 확인했습니다!

배움은 의무도 생존도 아니다